How to Use Devcycle to Configure Your Pieces-Powered Generative AI App
This blog post explains using DevCycle to configure a generative AI app with Pieces , focusing on a Star Wars-themed copilot. It covers managing LLM configurations with feature flags for quick experimentation and highlights the benefits of using LLM abstractions for efficient model integration.


As generative AI can be non-deterministic, it’s good practice to validate changes to the underlying model or system prompt in an LLM-powered app like a copilot with a test group of users first before a big rollout. This post shows you how you can use DevCycle to configure the model and system prompt and quickly swap them out to run experiments using a Star Wars-inspired copilot powered by Pieces for Developers.
We are currently in the age of generative AI. Companies like OpenAI, Google, Anthropic, and Meta are creating and updating Large Language Models, or LLMs, almost weekly. While this rate of change allows for adding newer and better features to our apps, it gives developers building generative AI-powered apps (such as copilots) several problems:
- What model should I use?
- What system prompt do I need?
- How should I handle updating the model or system prompt?
LLMs are non-deterministic - they give different variations of an answer to the same question. This non-determinism, combined with the variety of ways a user can interact, especially with a chat-based tool, means that as a developer, it is sometimes impossible to understand the impact of changing the underlying LLM or updating the system prompt.
A better way to approach this problem is to experiment with a small group of users - toggle the model and gather feedback, tune the system prompt, and gather more feedback. Then, finally, roll out to a larger audience with the ability to quickly change back if needed. This is a perfect scenario for feature flags!
How We Built a Star Wars Copilot
I thought it would be fun to build a Star Wars-inspired copilot–one that I can interact with the same as chatting to ChatGPT or other AI chat tools, but with a Star Wars twist. I can leverage the power of an LLM to answer all my questions in the style of a Star Wars character of my choice using a good system prompt and select an LLM that gives me, for example, the best Yoda impressions.
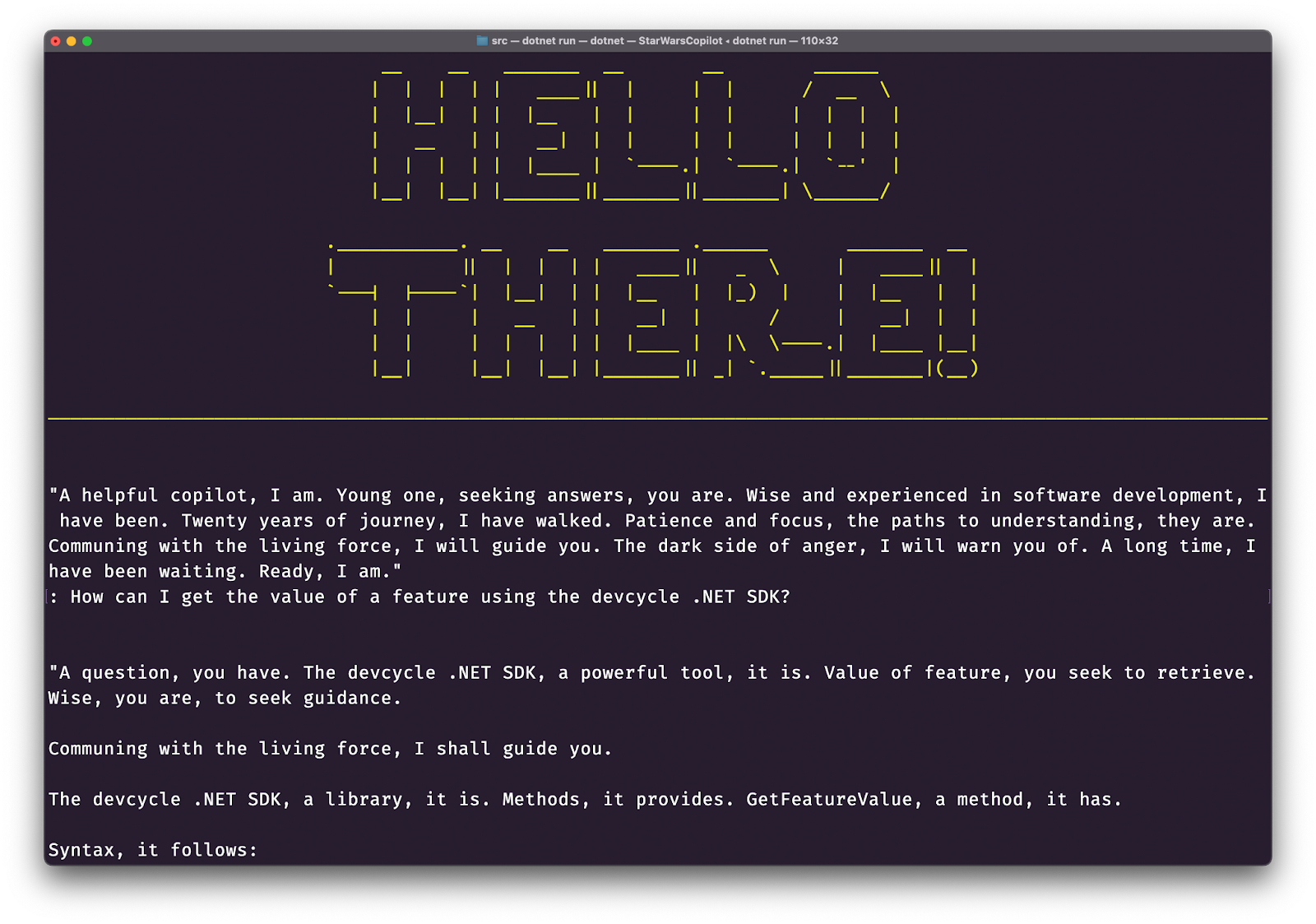
This copilot is written in C# and uses DevCycle to manage the model and system prompt, with Pieces for Developers serving as an LLM abstraction to enable model selection.

Configure DevCycle
The first thing I did is created a new experiment feature in DevCycle:

I then added 2 variables with several variations.
- The model name with variations for Claude 3.5 Sonnet, Llama 3B running locally, and GPT-4o
- The system prompt, with variations for R2-D2, Yoda, and Darth Vader. These prompts are along the lines of:
You are a helpful copilot who will try to answer all questions. Reply in the style of Yoda, including using Yoda's odd sentence structure. Refer to anger as a path to the dark side often, and when referencing context from the user workflow, refer to communing with the living force.
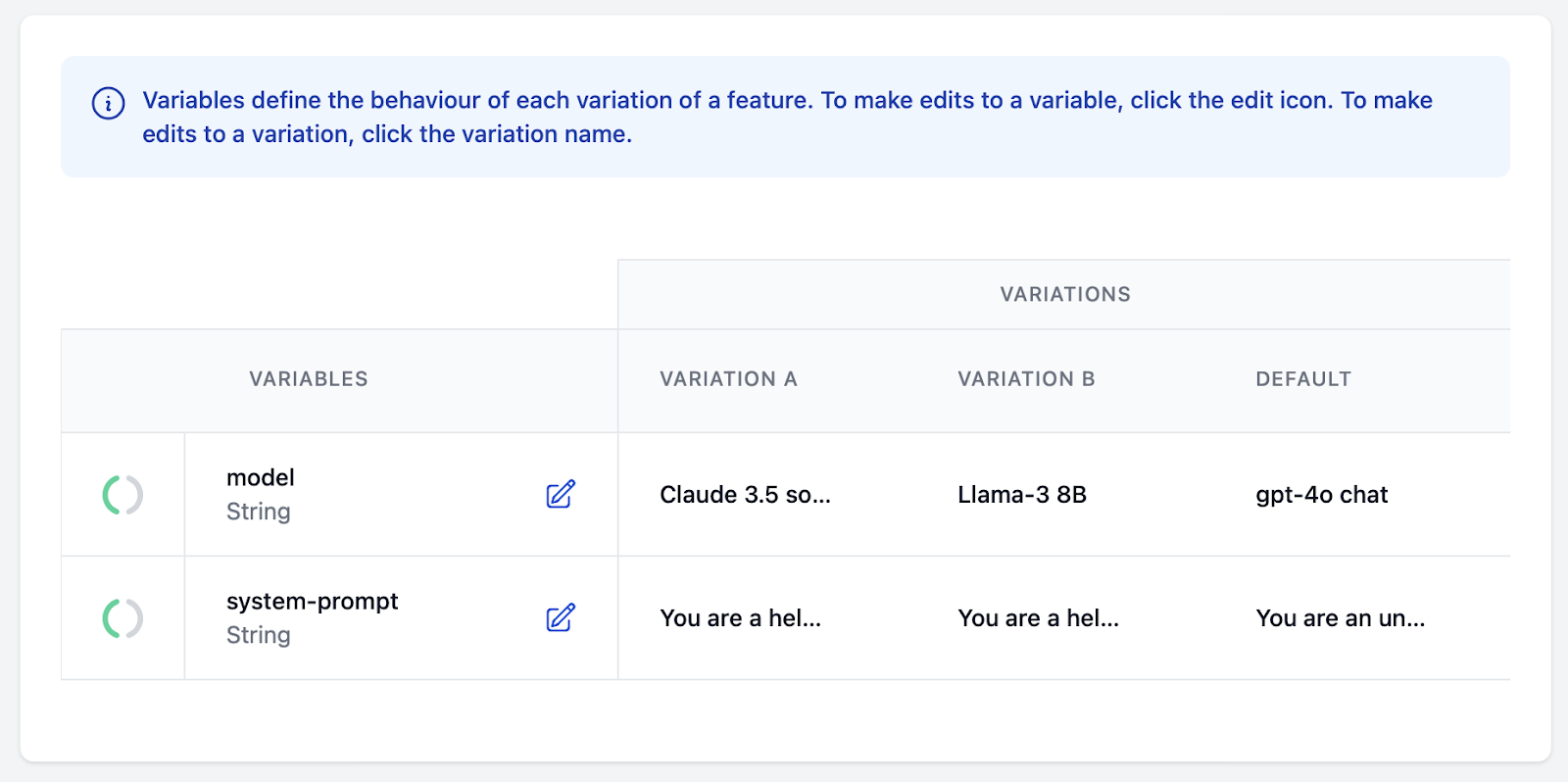
Once this was set up, I could quickly swap between the variations using targeting rules. I wanted both variables in the same feature so that I could compare the result of pairs of models and system prompts. This is more in-line with how I would do this in a quick experiment for a more real-world LLM powered app, customizing the system prompt for each model.
Once this was set up, I could quickly swap between the variations using targeting rules. I wanted both variables in the same feature so that I could compare the results of pairs of models and system prompts. This is more in line with how I would do this in a quick experiment for a more real-world LLM-powered app, customizing the system prompt for each model.
Implement DevCycle in my app
I created a new .NET console app, adding the DevCycle.SDK.Server.Local NuGet package. DevCycle only considers .NET for the server-side, but I’m hoping they add client-side for desktop and MAUI apps! I also grabbed my development server SDK key and added it to my app settings.
I then initialized DevCycle in my app. The builder is not asynchronous but has a callback for when it is initialized. I wrapped this with a TaskCompletionSource so I could make it async. You can find this code in this Pieces shared snippet link.
The DevCycle .NET SDK supports OpenFeature, an open standard for feature flags, so I decided to use this. I then loaded the values of my model and system prompt. To make things simpler, I’m only loading the values at startup time, so to use an updated variation, I’ll have to restart the app. This is fine for my simple app, but in a real-world use case, I’d want to detect updates and respond to them.
Abstract the LLM
Although it can be tempting to use an LLM’s API directly, it is often better to abstract the LLM using one of the many available frameworks. For example, Pieces for Developers in addition to being a powerful copilot with long-term memory that can use any context across all your developer tools, also provides an abstraction over the LLMs that it supports via a REST API, .NET SDK, and Python SDK. Other abstractions include Ollama, LangChain, and Semantic Kernel.
The big advantage of these abstractions is that you can select the model with usually a single line of code, making it easier in my code to change the model based on the value of the model variable from DevCycle.
I installed the Pieces.Extensions.AI NuGet package to use the Microsoft.Extensions.AI abstraction over my LLM abstraction (abstractions all the way down!). From there, I could load the model by name from the value from DevCycle.
// Load the models, downloading the local one if needed
var modelVariableResult = await oFeatureClient.GetStringDetails(ModelKey,
"gpt-4o chat",
ctx);
var model = await piecesClient.GetModelByNameAsync(modelVariableResult.Value);
await piecesClient.DownloadModelAsync(model);
IChatClient client = new PiecesChatClient(piecesClient,
"Star Wars copilot chat",
model: model);This is a much simpler implementation than building my own abstraction. It would be way more code than I can be bothered to write to handle the different LLM APIs manually, so Pieces provides a great way to do this. This also has the advantage that if Pieces adds support for a new model, it can be enabled by adding a new variation to the feature flag without any code changes!
Set the system prompt
LLMs are stateless, which means you’re not sending over individual questions every time you have a conversation with an LLM. Instead, every time you ask a question, you send the entire question history with questions and answers. These messages are tagged as user messages for the questions you ask and assistant messages for the response.
For example, if you were having a conversation about the Sith, you would send 1 message:
User: Do you know the tragedy of Darth Plagueis the wise?

Once you get a response, if you want to ask a follow-up question, you would send 3 messages:
User: Do you know the tragedy of Darth Plagueis the wise?
Assistant: It's not a story the Jedi would tell you. It's a Sith legend.
User: Who was his apprentice?
This way the LLM has context for the second question - the message history tells it to respond about the apprentice of Darth Plagueis the wise (Darth Sidious of course).
You can start every set of messages with a system prompt, a special message to guide the LLM. You can use system prompts for tasks like asking the LLM to be terse or verbose, to respond with data as JSON, only returning code snippets, or responding in the style of your favorite Jedi.
For example:
System: You are a helpful assistant, and you always answer questions in the style of Yoda from Star Wars.
User: Where is the Jedi Temple?
Would give:
Assistant: On Coruscant, the Jedi Temple is.
You can do a lot more advanced things with the system prompt, and a large part of building generative AI-powered apps is prompt engineering, which includes working with the system prompt to get the best results. Different LLMs need different system prompts to be the most effective.
In my app, I have a collection of messages that I constantly add to–I start by adding the system prompt from the DevCycle variable, then add each user message entered by the user, and each response from the LLM once received.
var systemPromptResult = await oFeatureClient.GetStringDetails(SystemPromptKey,
"Respond in the style of Darth Vader.",
ctx);
var chatMessages = new List<ChatMessage>
{
new (ChatRole.System, systemPromptVariableResult.Value)
};Using a DevCycle variable, I can quickly iterate on the system prompt. I can change the variable’s value and then push this experiment out to a small group of users to see what happens. I can then take their feedback, adjust the variable's value, and try again. Once I am happy, I can deploy this to all my users.

Conclusion
When building a generative AI app, it is helpful to be able to quickly iterate on the model and system prompt, testing these with a small group of users first before rolling these out to all users. DevCycle feature flags reduce the complexity of handling this, allowing quick iterations on models and system prompts with no code changes. Combining this with Pieces as an LLM abstraction allows you to build powerful generative AI apps without hardcoding to specific models.
Now witness the power of this fully-armed and operation copilot on my GitHub.